
Key Takeaways
- 1Traditional static PII redaction methods are brittle, costly, and lead to either destructive over-redaction or dangerous under-redaction.
- 2Distributed systems exacerbate the challenges of static redaction due to siloed data, semantic gaps, and the sheer volume of log data.
- 3An on-demand PII redaction architecture captures rich, contextual data from live applications only when needed, applying redaction at the source.
- 4Platforms leveraging runtime instrumentation, like Lightrun, implement this architecture by enabling dynamic logs and snapshots with built-in, policy-driven PII redaction.
- 5Robust governance, including RBAC, auditing, and AI guardrails, is crucial for a secure and compliant dynamic logging strategy.
Site Reliability Engineers and DevOps professionals are tasked with a difficult balancing act: ensuring system reliability with deep, real-time data while simultaneously protecting sensitive user information. For years, the conventional wisdom has been to log generously and then apply redaction rules downstream. This approach, however, is proving increasingly fragile and risky in the face of complex, distributed architectures.
Modern compliance frameworks like GDPR and CCPA, coupled with the staggering financial and reputational costs of data breaches, demand a more robust strategy. The old model of 'safe enough' logging, which relies on static, often brittle, filtering mechanisms, forces a painful compromise between observability and security. Engineers are often left with a choice: risk logging sensitive data or operate with redacted, context-poor information that slows down incident response. This article explores a superior architectural model that resolves this conflict.
Systemic Failure of Static, All-or-Nothing Redaction
Traditionally, PII (Personally Identifiable Information) redaction happens far from the code that generates the data. Most organizations implement it at the infrastructure level using one of two methods: either on the host via a logging agent like Fluentd, or centrally after logs have been shipped to an aggregator or observability platform. These systems typically rely on predefined rules, most often regular expressions, to identify and mask sensitive data patterns.
- While seemingly straightforward, this static approach presents problems that undermine both security and utility.
- Brittleness and Rule Decay: The most common point of failure is staleness. A developer pushes a code update that refactors a data model or alters a log message format. The centrally managed regex rule, now outdated, fails silently.
The system appears to be working, but PII is now actively leaking into your log streams. This problem becomes more acute in large engineering organizations where the team managing redaction rules is disconnected from the teams writing application code.
- Destructive Over-redaction: To err on the side of caution, security teams often implement overly broad redaction rules. For instance, a rule might mask all 16-digit numbers to catch credit cards. In doing so, it may also redact unique transaction IDs, correlation IDs, or other critical identifiers that are essential for tracing requests across a distributed system. The logs are 'safe,' but their diagnostic value is severely diminished.
- Costly Under-redaction: The inverse is just as dangerous. A new service is deployed that handles a previously uncontemplated piece of PII, like a government identification number. Because the central redaction configuration was never updated to include this new pattern, the data flows directly into logs unmasked. This is a common scenario in fast-moving development environments and, as many engineers have found in public forums like Reddit, a constant source of anxiety.
- Performance and Cost Inefficiencies: Applying dozens or hundreds of complex regex patterns to every single log line generated by a high-throughput application consumes significant CPU resources on the logging agent. This not only adds performance overhead to production servers but also increases the bill for data processing before the log even reaches its destination.
This static, 'all-or-nothing' approach can lead organizations into a permanent state of compromise. It treats all data as either completely safe or dangerously toxic, with no room for nuance.
The Compounding Challenge of Distributed Systems
Microservices, serverless functions, and Kubernetes add layers of complexity that challenge the assumptions of centralized a priori redaction. In a monolithic world, managing a single set of logging conventions was feasible. In a distributed ecosystem, it is nearly impossible.
Siloed Data and Semantic Gaps
Each microservice may be developed by a different team, potentially using a different programming language and its own logging library. Service A might log a user object as a structured JSON object, while Service B logs a flattened string. A single, central redaction policy cannot effectively or safely interpret these disparate formats. The context required to know that usr.eml in one service is the same as user_email_address in another is lost by the time the data reaches the logging pipeline, as noted by observers of modern data pipeline architectures like those at .
The Data Deluge
The sheer volume and velocity of log data generated by thousands of ephemeral containers or serverless functions make 100% inspection and filtering an enormous technical and financial burden. The cost of ingesting, processing, and storing this data forces engineering teams to make difficult decisions about what to log, often leading them to drop verbose debugging information in production. This preemptive data loss means that when an incident occurs, the critical information needed to resolve it was never captured.
A Better Approach: An On-Demand PII Redaction Architecture for Dynamic Logging
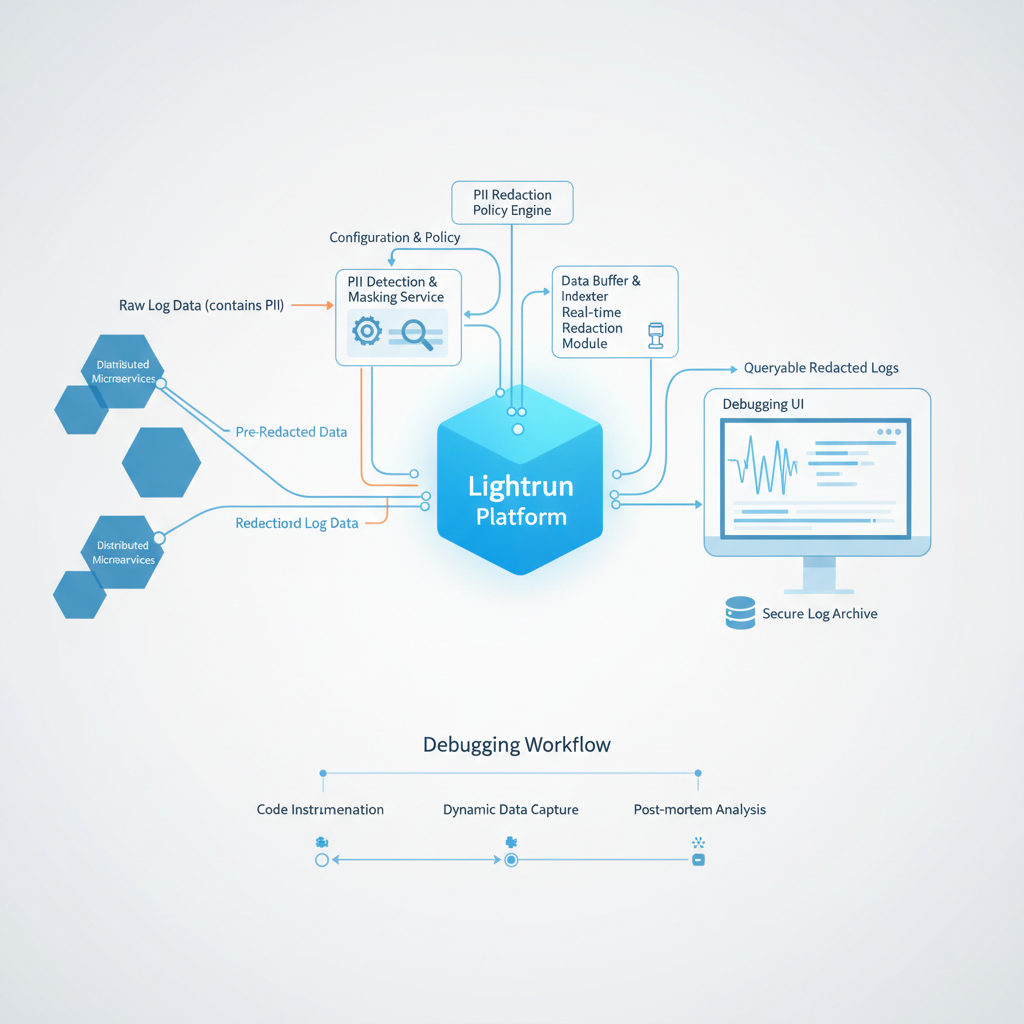
Instead of attempting to sanitize a firehose of always-on log data, a modern architecture inverts the model. It enables engineers to fetch rich, contextual data from a live application precisely when it is needed, applying redaction at the source, at the moment of collection. This is the core principle of a PII redaction architecture for dynamic logging in distributed systems.
- This architecture is defined by several key characteristics.
- On-Demand: Telemetry is not continuously streamed. It is captured for a limited time in response to a specific diagnostic need, reducing data volume and processing costs.
- Source-Level Context: Data capture and redaction happen inside the running application process. At this point, the system has full access to the original data types, variable names, and code context, allowing for more intelligent and accurate redaction than regex-on-strings can provide.
- Policy-Driven: Redaction rules are still managed centrally for governance, but they are applied dynamically at the source by the instrumentation agent, ensuring consistency across all services.
- Fully Auditable: Every request for on-demand data is a discrete, attributable event tied to a specific user and their intent, creating an immutable audit trail for compliance.
This model moves away from speculative, pre-emptive logging and toward intentional, just-in-time data collection.
Implementing On-Demand Redaction with Lightrun
This architectural theory is put into practice by platforms built on Runtime Instrumentation, such as Lightrun. Lightrun allows SREs and developers to add logs, metrics, and traces to live applications without code changes, redeployments, or service restarts. This capability is the foundation for a secure, on-demand data strategy.
- Here’s how Lightrun operationalizes this new architecture.
- Dynamic Logs and Snapshots: Instead of adding permanent
logger.debug()lines to code, a developer uses the Lightrun IDE plugin to place a Dynamic Log or a Snapshot on any line in a running application. A Dynamic Log captures a specific variable or expression, while a Snapshot captures the entire stack trace and all local variables. This data is only generated while the Lightrun action is active and is streamed directly to the engineer who placed it.
- Built-in PII Redaction Engine: Lightrun includes a policy-driven PII Redaction capability. An administrator defines a set of sensitive data patterns (by name, such as 'email,' 'firstName,' or 'ssn,' or by regex). When a developer requests a Snapshot, the Lightrun agent intercepts the data *before it ever leaves the application boundary*. The agent inspects the variable names and values, redacts any information that matches the central policy, and only then transmits the sanitized data. This ensures that sensitive data never leaves the production environment, not even in-transit to the developer's machine.
Code in Practice: Safely Debugging a Live Service
Lightrun actions are not written in application code; they are overlaid on it at runtime. The following code snippets show typical application code, with comments indicating where a developer would insert a Lightrun action from their IDE to safely gather Runtime Context.
Java: Investigating an Order Processing Failure
In this example, an SRE needs to inspect a failed order object in a production OrderService. The Order object contains customer PII.
1public class OrderService {
2
3 private final OrderRepository orderRepository;
4 private final PaymentGateway paymentGateway;
5
6 // ... constructor ...
7
8 public Order processNewOrder(Order newOrder) {
9 // A production issue is causing some orders to fail validation.
10 // An SRE needs to inspect the full 'newOrder' object to understand why.
11 // The Lightrun agent will automatically find and redact fields like
12 // newOrder.customer.email and newOrder.paymentDetails.creditCardNumber
13 // before sending the data to the SRE's IDE. A Lightrun Snapshot can be placed here to capture the 'newOrder' object.
14
15 if (!validateOrder(newOrder)) {
16 throw new InvalidOrderException("Order validation failed for ID: " + newOrder.getId());
17 }
18
19 paymentGateway.charge(newOrder.getPaymentDetails(), newOrder.getTotal());
20
21 // This log is only generated when active, incurring minimal cost or overhead otherwise. A Lightrun Dynamic Log can be placed here to output: "Order {newOrder.id} successfully processed for customer {newOrder.customer.id}"
22
23 return orderRepository.save(newOrder);
24 }
25
26 private boolean validateOrder(Order order) {
27 // ... validation logic ...
28 }
29}Python: Diagnosing a User Profile Update
Here, a developer is debugging an issue with a user profile update in a Python web application. They need to see the incoming data without viewing the user's personal email or phone number.

1# main.py
2import lightrun
3from flask import Flask, request
4
5# Lightrun agent initialization (typically includes company_key in production)
6try.
7 lightrun.enable(company_key='YOUR_COMPANY_KEY')
8except Exception as e.
9 print(f"Failed to initialize Lightrun agent: {e}")
10
11app = Flask(__name__)
12
13def internal_update_service(user_id, data).
14 # Mocking service for functional code
15 return type('obj', (object,), {'is_success': lambda: True})()
16
17@app.route('/user/<int:user_id>/profile', methods=['POST'])
18def update_user_profile(user_id).
19 profile_data = request.json
20
21 # Lightrun Dynamic Log placed via IDE here.
22 # Log: "Attempting profile update for user_id={user_id}. Data: {profile_data}"
23
24 result = internal_update_service(user_id, profile_data)
25
26 if result.is_success().
27 return {'status': 'success'}, 200
28 else.
29 return {'status': 'failure', 'reason': result.get_error()}, 500The Governance Layer: RBAC, Auditing, and AI Guardrails
A true PII redaction architecture for dynamic logging in distributed systems must also include strong governance controls.
Technology alone is insufficient. Lightrun provides this through features like RBAC (Role-Based Access Control), which allows organizations to manage user access to resources like specific agents and sets quota limitations on their use. Every action taken is recorded in a comprehensive audit log, providing a full record for compliance reviews.
These guardrails are becoming even more critical with AI. As organizations adopt AI SRE and multi-agent systems to automate incident response, these autonomous agents need access to high-fidelity runtime data. Feeding them raw, unredacted production data is a significant security and compliance risk. Recent research and best practices from cloud providers like AWS and academic papers on multi-agent architectures emphasize the need for robust redaction pipelines. A dynamic instrumentation platform with built-in PII redaction serves as the essential guardrail, providing AI agents with the sanitized runtime evidence they need to operate safely and effectively.
The final piece is connecting this safe, rich data back to engineers where they work. By delivering information directly into an IDE plugin, the entire feedback loop is shortened, eliminating the need to pivot between application code and separate observability dashboards.
By moving from a static, reactive redaction strategy to a dynamic, proactive one, engineering organizations can finally resolve the conflict between deep observability and data security. This modern approach not only strengthens compliance but also accelerates debugging, reduces costs, and empowers developers to build and maintain more reliable systems.
To learn more about how to implement a secure, on-demand logging strategy built on runtime instrumentation, explore how Lightrun enables developers to add logs, metrics, and traces to production in real time: Lightrun's platform


